Can Academic Science Keep Up with the AI Frontier?
Tracking the meteoric rise of AI foundation models in science and the constraints on future breakthroughs.

If you listen to leaders of frontier AI labs, generative AI should precipitate a phase change in scientific research any day now. Demis Hassabis says we are on the cusp of unleashing a “golden era for scientific discovery” in the next 10 years, a “new Renaissance.” Dario Amodei estimates we will compress 50-100 years of research in biology and medicine into just 5-10 years. Sam Altman predicts AI will facilitate “astounding triumphs – fixing the climate, establishing a space colony, and the discovery of all of physics.” Frontier labs are not predicting iterative innovation, but revolutionary transformation.
We here at FutureTech remain cautiously ambivalent about the magnitude of these claims. But AI’s transformational impact on science is directionally correct, and we need not prophesize to claim this. For scientists, AI enabled methodologies are neither a recent innovation nor a punctuated transition. Quite the contrary: the use of AI models across science has been growing near-exponentially for well over a decade, across nearly all domains of science.
In our new paper The Rapid Growth of AI Foundation Model Usage in Science, we document this historical trend with unprecedented depth, tracking who has adopted which foundation models and how scientists deploy them in their methodologies. We construct the largest dataset of its kind – classifying 750 thousand academic citations of nearly 2 thousand foundation models across 250 thousand papers. In this post, we’ll not only demonstrate the staggering growth of AI in science over the last decade, but we’ll look under the hood at which models are used, how that impacts scientific outcomes, and why it matters. Expect to learn:
Which fields are currently using AI foundation models most often, growing that use the fastest, and using the largest models?
How quickly are scientists keeping up with the AI frontier? How do research outcomes change as scientists move closer to the frontier?
What bottlenecks in AI may be limiting scientific breakthroughs of the sort predicted by frontier labs?
To begin, we’ll set the stage with a fundamental question: what is an AI foundation model, and how do we track their deployment in science?
What do we mean by “AI foundation models”?
The term “AI” means different things to different people. Before we can track how scientists are using AI, we need to agree on some definitions. Is a chess engine like IBM’s DeepBlue – hardcoded with domain knowledge, deterministically navigating through search space – considered AI? What about a simple linear regression model, fit using gradient-based methods? Are we just being obnoxiously pedantic? Perhaps, like Justice Potter Stewart, we’ll just know it when we see it!
Sadly, we won’t. The literature has no standard definition of what “AI” means in the context of scientific methodologies. For instance, this paper uses a list of keywords to indicate the presence of AI, but they seemingly don’t publish that list anywhere. This report from Stanford uses an elaborate ontology to classify titles and abstracts, but eventually uses word embeddings – an uninterpretable way of defining AI statistically – to approximate AI topic engagement. This study even includes support vector machines, which are hardly more deserving of the “AI” label than drawing a line through a scatter plot.
We take a more concrete approach. Rather than asking about anything which could be AI, we focus more narrowly on scientists using specific existing AI models such as AlexNet, BERT, or GPT-4. These so-called foundation models are deep learning models which required high upfront costs at the time of training (e.g. compute, data, expertise), but are general enough to be (cheaply) reused for a variety of scientific tasks. Our dataset is constructed as follows:
We first curate a list of foundation models, a comprehensive set of their metadata, and the papers which introduced them.1 This allows us to track more than the mere presence of AI, including model size, modality, openness, age, institution of origin, and much more.
We use academic citation graphs to track which publications cite papers that introduced a foundation model. For each citation, we find the exact context of the citation, while also extracting comprehensive metadata on the citing paper. This provides a more accurate signal for AI engagement than paper abstracts or keywords, while still being compute efficient.
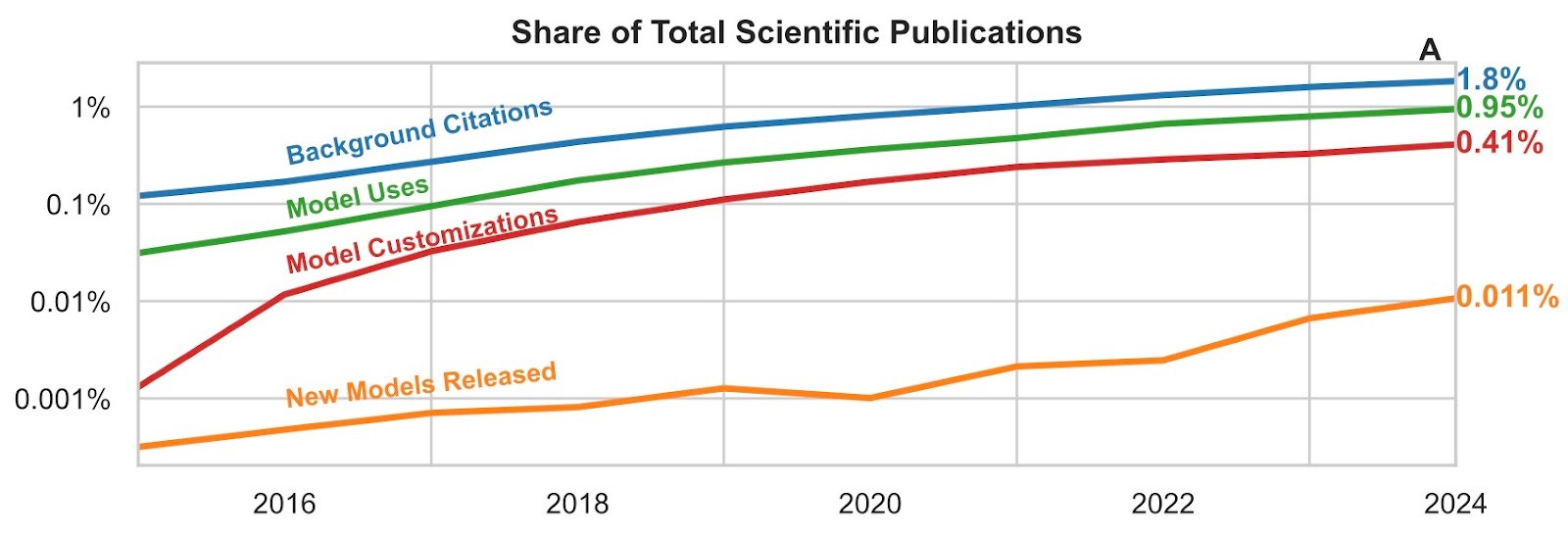
Finally, each time a foundation model is cited, we classify the citation context into one of three categories: background (just mentioning the model), usage (taking the model as-is, off the shelf), and extending (adapting/fine-tuning the model). This classification is essential when leveraging citation network patterns: counting all citations would overestimate true adoption rates by 141%.
Together, this dataset lets us answer questions about specific patterns of model adoption in unprecedented detail. Which fields are using the largest models? The oldest models? Which fields require the most fine-tuning? Which countries and institutions dominate among adopters?
In this post, we will focus on differences between scientific domains, and save questions about who is adopting foundation models for later posts. Enough with the methodological minutia, let’s get to the results!
All Fields See Near-Exponential Growth
From a bird’s eye view, we see that the adoption2 of foundation models across all of science has been growing near-exponentially for almost a decade. By 2024, more than 1% of all academic publications adopted a foundation model, with around one-third actively customizing (extending). The share of adopters in the literature has grown more than 33x over the last decade.
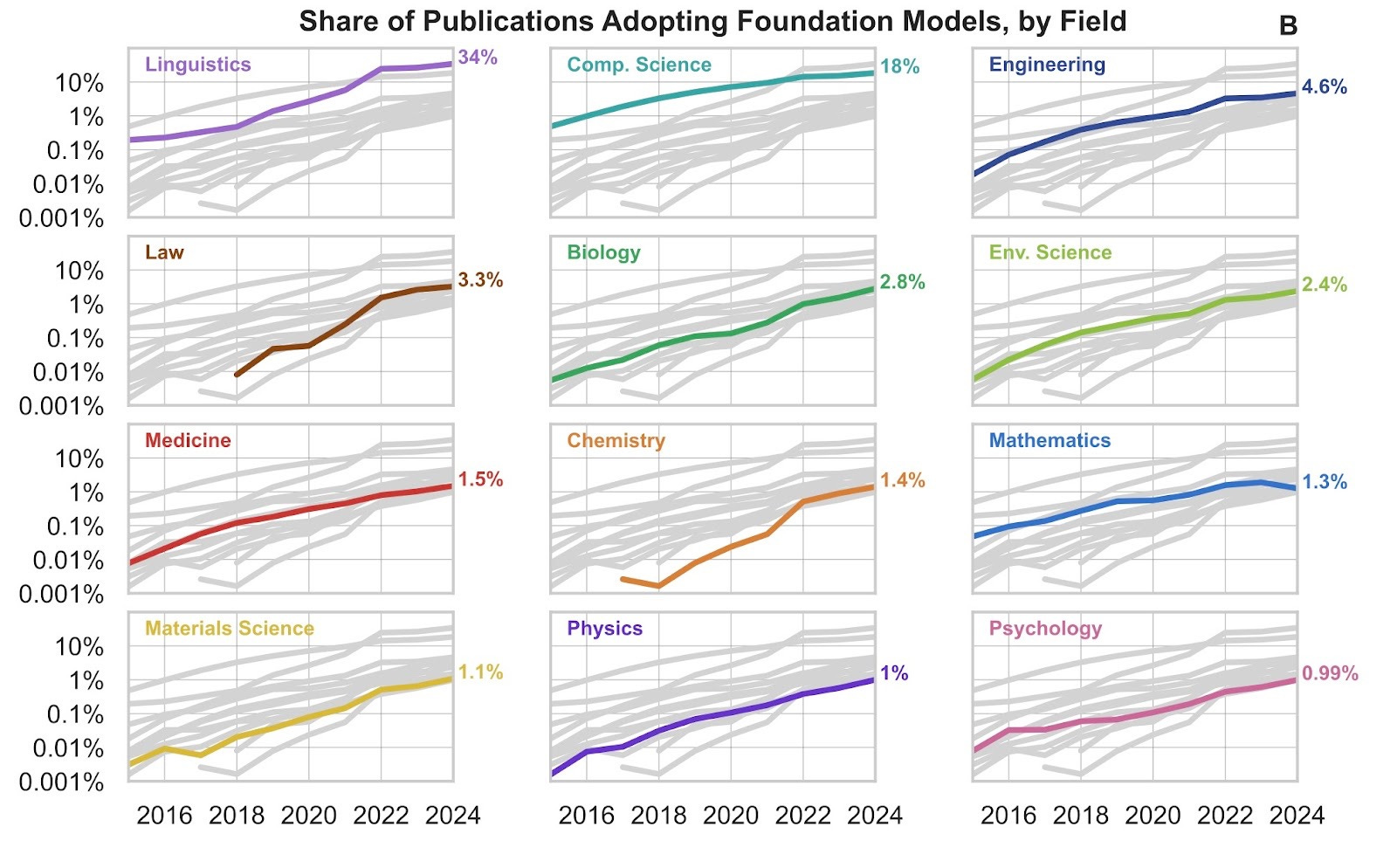
This trend isn’t restricted to a few strands of the literature either. We see staggering growth across all domains, from Computer Science and Engineering to Linguistics and Psychology. Among these fields, Linguistics (34%) and Computer Science (18%) stand out with the higher adoption rates, perhaps unsurprisingly.3 But nearly every field in our analysis reached 1% adoption by 2024 – domains like History and Sociology included – highlighting the diverse potential of foundation models across disciplines.
Many fields with lower adoption rates still show astonishing growth rates. Biology and Chemistry exhibit the fastest growth for model usage (off-the-shelf adoption) with 3-year compound growth rates of 123% and 168%, respectively. Both of these fields also exhibit strong growth in model customization, but Psychology is racing ahead of the pack with a 107% annual growth rate. (See Table 1 for a more complete breakdown.)
This extraordinary growth doesn’t tell the full story. Scientists are using AI more now than ever before, but which models are they using? When we analyze the properties of models being adopted by researchers, we don’t find the same story of rapid growth.
Bigger Does in Fact Mean Better
In AI, bigger models are more costly to use. But bigger models are also better models. That’s not just a rule of thumb: the size of a model (and training dataset) predicts its performance with extraordinary accuracy according to neural scaling laws.4 That predictability is great news if you are a frontier lab detonating your longest ever training run. But for compute constrained scientists, scaling laws have a different take home message.
Neural scaling laws are power laws of compute with very small exponents. These power laws change very, very slowly, such that smaller and smaller performance improvements require larger and larger models. A few GPUs might be helpful for running smaller models, but if you need frontier performance, those GPUs may quickly become as useful as a TI-84.
Scientists are adopting foundation models more than ever, but given the importance of model size for performance, are those models also getting bigger? We observe that the size of adopted models is growing, but it’s growing slowly – far slower than the size of models being built at the frontier. In 2013, the median model built was 7.7x larger than the median model adopted. By 2024, that number jumped to 26x. The models adopted by scientists aren’t keeping pace with exponentially increasing sizes at the frontier.
Some fields are doing better than others, though. Psychology, Linguistics, and Law lead the pack in 2024 as the only three fields adopting (on average) models with more than 3 billion parameters.5 Computer Science sits in the middle, while Materials Science, Environmental Science, and Engineering bring up the rear under 100 million parameters.
Perhaps fields like Psychology or Law needed LLMs before AI could be of substantial use for most applications, whereas Materials Science or Engineering can still find use in small models at the AlexNet scale. This explanation is supported by the contribution of language models to recent growth in adopted model sizes. From 2022 to 2024, average size of models adopted by scientists increased by 3.9x. But if we restrict adoptions to only language and multimodal models, sizes increase by 5x and 11x, respectively.
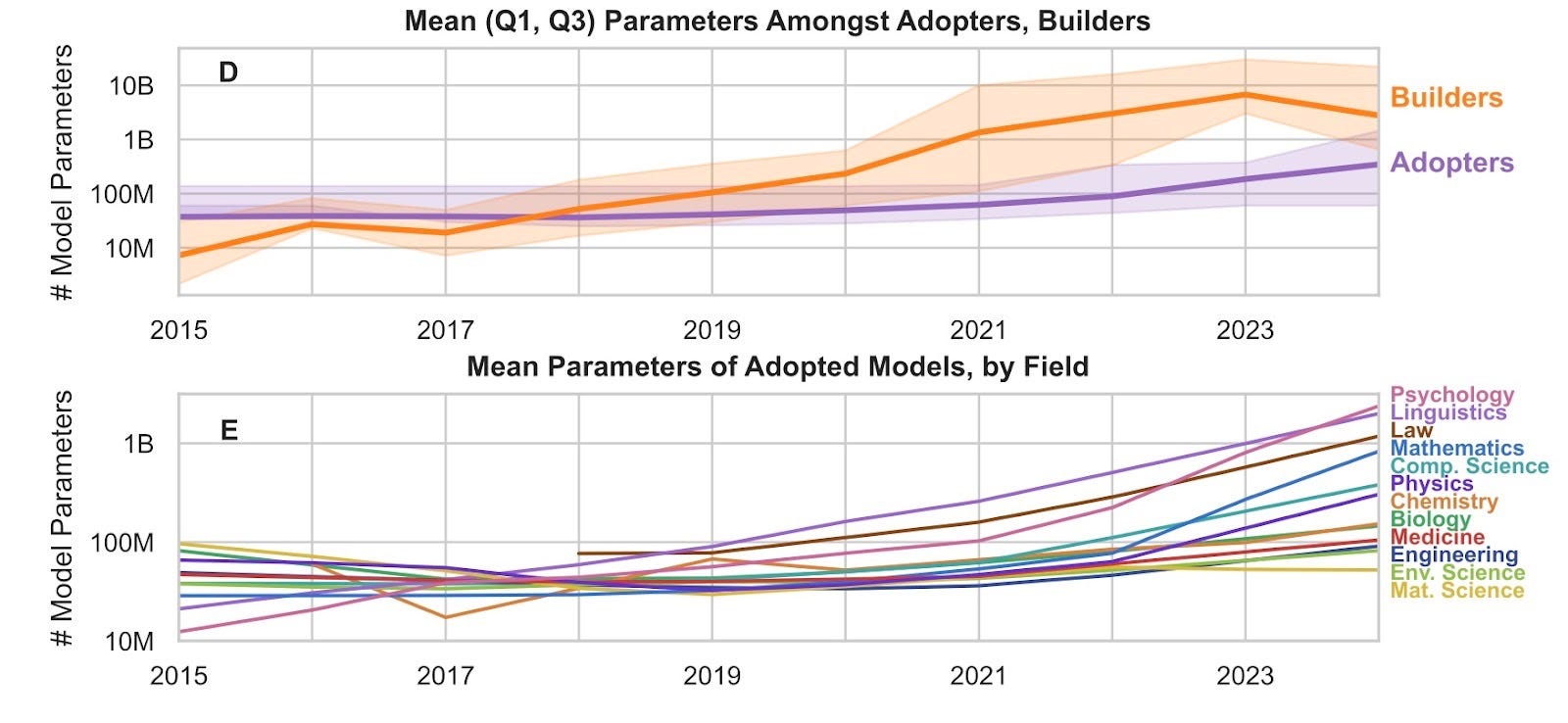
This lag also exists when measuring the age of the models. The average age of models adopted (at the time of use) is at least 3.3 years old across all fields. Linguistics and Law use the newest models (3.3 and 3.8 years old, respectively), which is consistent with the hypothesis presented above. Perhaps surprisingly, Mathematics is far less cutting-edge (5.7 years), despite modern LLMs abilities in competitive mathematics and novel research. Though this could be from lagging diffusion, mathematics may also be especially prone to leveraging frontier models without citation. Bringing up the rear is Physics (5.9 years) and Materials Science (6.1 years), straying far from the cutting edge, but consistent with the hypothesis that certain fields can still squeeze value out of older, smaller models.
Of course, these differences only matter if newer, bigger models translate into better scientific outcomes in practice, not just in theory. And indeed, this is exactly what we find (though only correlationally). On average, since 2020, increasing the size of an adopted foundation model 10x corresponds to 1.3x more citations. That same 10x also corresponds to higher-quality journals, with an average increase of 2.3 points in journal impact factor.6
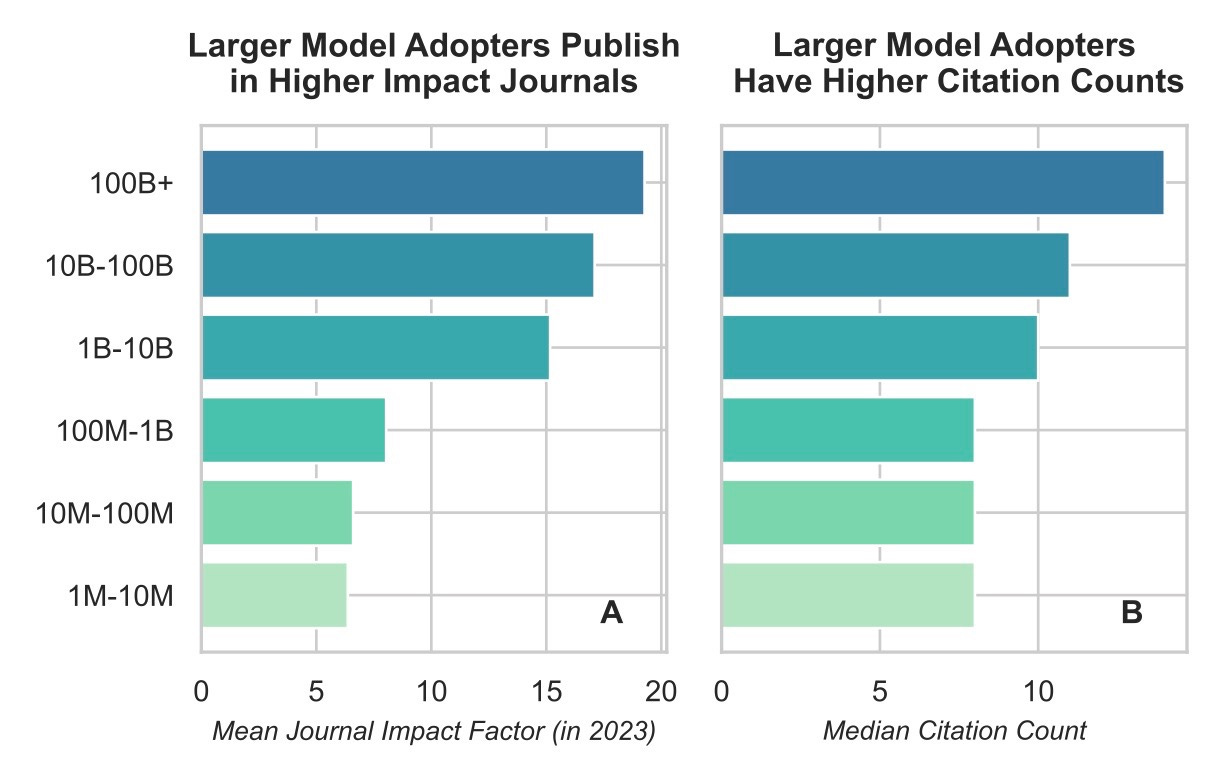
We suspect using larger models yields better performance, better research, and therefore better publication outcomes. Of course, it’s possible the causality could go in the opposite direction: teams that publish the best papers may accrue more computing resources and be free to use larger models. Or there could be some third factor: for example, maybe working in industry leads to both better outcomes and more resources. But in each of these, the correlation we find is still suggestive. Why do researchers with ample compute choose to use bigger models, which still take more time and resources to run? Why would industry allocate precious compute resources to research if it weren’t necessary for better results?
Scientists Are Clearly Compute Constrained
Our findings suggest that the best science is done with the biggest models. But bigger models also require more computing power. Sadly, academic science is notably constrained by insufficient computing resources. In fact, the “compute divide” between public and private science is growing rapidly.
Observing the top 500 AI supercomputers across the world, we see that the share of public ownership has fallen rapidly, from 61% in 2019 to 12% in 2025. Public ownership went from a healthy majority to a miniscule fraction over barely half a decade. Infrastructure investment looks even bleaker. The most notable public sector investment is the NSF’s recent National Artificial Intelligence Research Resource (NAIRR) pilot program, which by mid-2024 had delivered a total compute capacity equal to 5,000 H100 GPUs. That’s a great start, but 5,000 distributed across many universities is missing a few zeros from top industry counts like Microsoft (150,000), Meta (150,000), Google (50,000), or Amazon (50,000).
At MIT FutureTech, we’ve focused on this issue for years. We directly observed this compute divide by comparing the sizes and shares of foundation models built between industry and academia. We’ve documented that AI-intensive research is more dependent on capital – like computing resources – than traditional research (which depends more on human labor). Now this most recent paper shows that AI is becoming a cornerstone of modern science, but outcomes may be compute constrained. We believe that scientific research – particularly non-proprietary discoveries – are an essential source of economic growth and progress. To fully reap those benefits, scientists will need enough resources to discover the next generation of breakthroughs.
This post was written by Alex Fogelson. Ana Trišović, Zachary Brown, Sebastian Sartor, and Neil Thompson provided editorial feedback. Lucy Yan provided logistic support. The authors of the paper are Ana Trišović, Alex Fogelson, Janakan Sivaloganathan, and Neil Thompson. For correspondence on the paper, please contact Ana Trišović or Neil Thompson.
Until recently, state-of-the-art models were almost always introduced in academic publications.
Adoption is defined as either using or extending a model, not merely citing it as background.
Papers can have multiple associated fields. For example, a paper using CNNs to classify stained cell samples would span both Computer Science and Biology. For this reason, adoptions across domains overlap heavily with Computer Science.
Bigger is not always economically better, but performance nearly always increases with model size provided you have enough training data.
For reference, that’s 100-1000 times smaller than current state of the art language models.
These results hold when including domain and year fixed effects.