How Much Would It Have Cost Claude Shannon to Train Claude Opus?
The hidden role of hardware efficiency — and why the next ten years will tell us where AI goes next


Scientists have been working towards computers that can think since Turing formalized computational universality in 1936. But only in the last few years have computers managed to achieve long-held goals like passing the Turing’s test or reasoning in natural language. Why did this take so long? And why has progress been so dramatic in the last ten years?
Today’s AI developers have access to a number of resources that the would-be AI-builders of yesteryear lacked:
Better algorithmic / architectural ideas,
More training data,
More efficient computing hardware,
And more cash to spend on that computing hardware and data.
Growth in each of these inputs has been necessary to reach modern AI capabilities. But growth has been historically uneven, and as a result, AI progress has been bound more by some inputs than others.
We’ll argue that hardware efficiency in particular has been the binding constraint on model capabilities over the last 70 years. The steady pace of hardware efficiency progress – described by Moore’s law – only recently brought us to the point where rapid investment in hardware quantity could close the last mile, which we’ve seen over the last decade. That investment would be for naught without the prior half-century of hardware efficiency progress.
Going forward, it’s reasonable to expect that the steady march of hardware efficiency progress will continue. But the rapid pace of investment we’ve seen recently cannot continue indefinitely unless it leads to dramatic and sustained economic growth. If transformative AI – transformative enough to bring about that kind of growth – is achievable with only a few more orders of magnitude of investment, then… buckle up! But if it isn’t, AI investment will eventually need to slow to an economically sustainable growth rate, commensurate with the returns on investment. In that scenario, AI progress may once again depend heavily on the slower pace of hardware efficiency progress.
In this post, we’ll examine the history of AI progress and assess the role of each of the four inputs. We’ll then explain why the next ten years of AI progress will be an extremely important signal for AI’s future trajectory.
This post is based on a talk delivered by Dr. Neil Thompson at the AI for the Economy Forum, which FutureTech co-hosted with Google last month. You can view that talk here.
We had the ideas, but not the compute
A typical history of an area of science emphasizes the importance of ideas. Perhaps surprisingly, though, many of the foundational ideas in AI were conceived of in the 1950s and 60s, but lacked sufficient resources to be implemented. In other words, algorithms were probably not the binding constraint on AI progress.
In a seminal 1948 paper, Claude Shannon, the founder of information theory (and the namesake of Anthropic’s Claude model), showed that it was possible for statistical measures to predict the next “token” of English language text given the preceding words. In the very same paper, he established the concept of entropy as a metric for evaluating the predictive performance of such models – the foundation of the measures we use today. Just a few years later in 1957, Frank Rosenblatt would invent the perceptron – the fundamental unit of modern deep learning. Modern systems combine millions of these digital neurons into networks, requiring massive amounts of compute to train, but even then researchers were already starting to scale perceptrons into larger neural networks, given what their available hardware would allow.
Of course, some key algorithms were admittedly still missing, but important precursors were often already around. Rosenblatt himself had already discussed the possibility of “deep” networks as early as 1962. And while backpropagation – an essential algorithm for training deep networks – would not enter general use in AI until the mid-1980s, early versions of backpropagation were actually already discovered and discussed numerous times before then.
The existence of so many essential ideas in the middle of the twentieth century lends support to the idea that algorithms were ahead of what was implementable at the time, given the hardware and training data available.
That implementation took time. It would take another 30 years before neural networks and text prediction could be connected and put into practice. In 1988, IBM created Candide, a statistical machine translation system which was trained on the Canadian Hansard, a digitized text corpus just large enough to train an n-gram model (a phrase coined by Shannon). Just two years later, Jeffrey Elman proposed using recurrent neural networks to model the next token of text..
Algorithms and data are downstream of compute
We don’t want to downplay that ideas like Elman’s required ingenuity, or suggest that ideas since the 60s have been trivial or unimportant for AI progress. We only want to suggest two things: first, that a lot of the essential ideas were floating around much earlier than they were eventually implemented and validated in AI systems. And then second: if more computing power and training data had been available for researchers in the past, the remaining algorithmic insights needed to reach today’s frontier might have been discovered even sooner. Why? Impressive results would have made it clear earlier which research directions were most promising, incentivized algorithms that take advantage of raw computational power, drawn new researchers into the field, led to earlier real-world usage of neural networks, and attracted more investment.
This idea, that lack of computing capacity constrained innovation, is not just our modern, retrospective diagnosis. Writing in 1990 on the previous thirty years of progress in neural networks, Bernard Widrow and Michael Lehr emphasize that it was indeed the available hardware that constrained the models researchers could build: “Today, most artificial neural network research and application is accomplished by simulating networks on serial computers. Speed limitations [a result of compute limitations] keep such networks relatively small [...]”
Just as algorithmic ideas might have matured sooner if more hardware was available for experiments, the massive digital text datasets we now have are also downstream of progress in hardware. In particular, internet scale data requires the internet, a massive population of internet users contributing text, and sufficiently cheap, powerful hardware (with inexpensive high-capacity memory) for ubiquitous personal computing in developed countries.12
We’ve argued that compute was the binding constraint. But was it lack of investment in compute – could early AI researchers have simply purchased more hardware? Or was it the efficiency of the hardware on offer?
The latter. To see why, let’s pose a counterfactual thought experiment: how much would someone like Claude Shannon – one of the greatest computer scientists of the mid-twentieth century – have needed to spend to train an AI model of today’s capabilities with the hardware of his time?
The cost of Claude in 1946
Today’s frontier models, like Claude Opus, require massive amounts of compute – around 1026 FLOPs. Throwing aside the need for new algorithms and data, let’s look at what it would take to build such a thing with the hardware of Shannon’s era – the mid-forties.
In 1946, the Electronic Numerical Integrator and Computer (ENIAC) was built for the United States Army – the first programmable, electronic, general-purpose digital computer. ENIAC was a landmark, Turing-complete, fully reprogrammable machine. It cost the equivalent of $7 million in 2024 and operated at about 500 FLOPs per second. We’ll use ENIAC to ground our first estimates – full calculations are detailed at the end of this post.
Since we know ENIAC’s power consumption, historical pricing, and cost of construction, we can back out an estimate for dollars per FLOP and extrapolate to 1026 FLOPs. The final number: about $9 billion trillion in present-day dollars to train a Claude Opus equivalent in 1946. That’s 70 million times more than current world GDP. Even if Shannon had wanted to buy this much computing power, it was beyond infeasible for the economy of his time.
Before comparing that figure to today’s cost to build Claude Opus, let’s take a pitstop in 2012, right at the cusp of the deep learning revolution. In the halls of the University of Toronto, Geoffrey Hinton and two soon-to-be-famous graduate students are training what will eventually be known as AlexNet – a pioneering image recognition model which bet on scaling compute as a way to yield better performance. How much would it have cost Hinton to train Claude Opus instead of AlexNet?
We’ll again use the largest supercomputer in the world at the time for reference. The TITAN supercomputer had just been built at a cost of $97 million. It was capable of 2.7 x 1016 FLOPs per second and drew 8200 kW of power. Using a similar calculation with estimates for power draw and cost, it would cost $12 billion in present-day dollars to train Claude with many TITANs. Given the improvements in hardware efficiency from ENIAC to TITAN, training Claude in 2012 would have been hypothetically feasible for a nation-state or megacap company, even if the cost was still beyond what would have been accessible to Hinton and collaborators.
Today? With the same FLOP extrapolation on contemporary compute, it would cost around $105 million to train Claude Opus in 2026. Note the cost reductions: from Shannon to Hinton, we see a 719 trillion-fold reduction in cost. But from 2012 to the present, we see a mere 114-fold reduction. By these stylized examples, efficiency increases from Shannon to Hinton were more than 6 trillion times more than from Hinton to the present.
Across the same time periods, the growth in compute investment rather than hardware efficiency is far less dramatic. Across notable machine learning models, the investment growth from 1946 to 2012 is only around 600x more than the growth from 2012 to the present, on average.3 Hence, from Shannon to Hinton, we see almost 2,000x more growth in hardware efficiency than investment. But from Hinton to today, we see more than 6,000,000x more growth in investment than hardware efficiency.
This divergence is consequential: the last decade has seen tremendous investment with minimal efficiency gains, but rides on the back of 60+ years of efficiency accumulation – billions upon trillions of times more efficient hardware. While current capabilities are in part the result of rapid growth in compute buildout by frontier labs, they stand on the shoulders of a half-century of Moore’s law.
The next ten years of progress matter a lot
We’ve seen that historically, the slow march of hardware efficiency has played a much larger role than the recent boom of compute investment. What does that mean for the future of AI progress? We see roughly three possible universes.
In the first universe, true transformative AI is only a few orders of magnitude away. Frontier labs can simply reach up and grab it with enough short-term spending, provided they can find investors who can front the cash without requiring immediate returns. In this world, hardware progress over the last 70 years has taken us just short of the end zone, and we can reap the full rewards with one last monumental push.
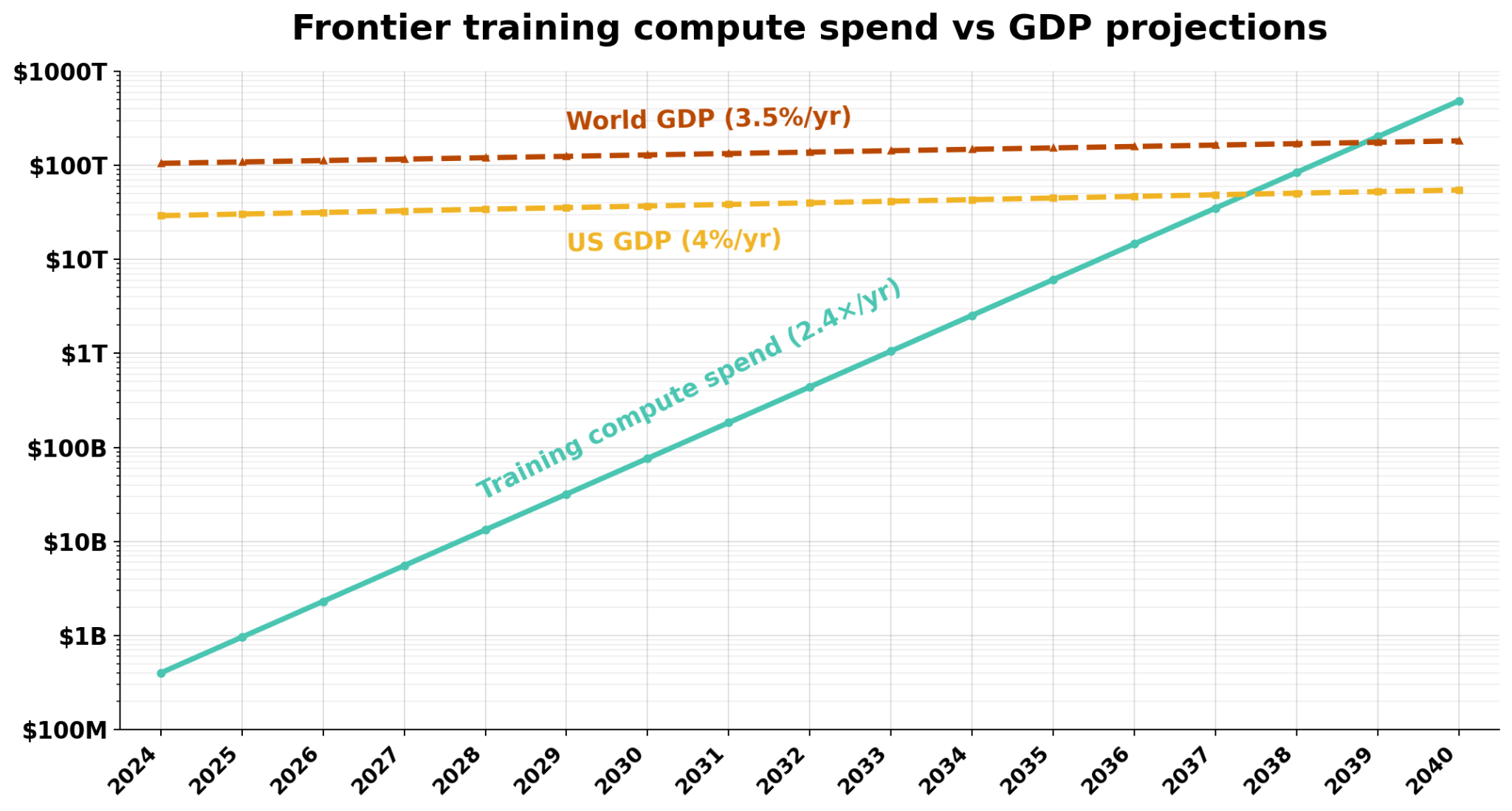
However, training compute cannot increase indefinitely without world-historical economic returns. A naive extrapolation of current spending would have frontier model training compute spending exceed world GDP by 2040. It’s not plausible that there is enough patient liquid investment capital to reach this point. So if we don’t see transformative AI in the next several orders of magnitude of scaling, that brings us to the second universe.
In the second universe, transformative AI doesn’t arrive soon, and those capital constraints mean that hardware investment must slow to match the pace of economic returns. However, capabilities improvements do bring in enough revenue that investment still proceeds at a relatively rapid pace, and progress is still driven mostly by hardware investment. The pace of progress is faster than what we’d see from hardware efficiency alone.
In the final universe, the next breakthrough is again many orders of magnitude away, and the utility of training more expensive models diminishes fast enough that scaling cannot pay for itself. Companies cannot find a way to economically continue exponential scaling, and we are instead forced to wait decades for hardware progress to slowly accumulate. Just like Claude Opus was simply out of reach for Claude Shannon, it may be that no short-term investment can substitute for the gradual progress of decades.
The next few years are critical for determining which of these paths we are on. If the CEOs of frontier labs are correct, we could see transformative AI in the next few years as the labs make their final push. Short of such a breakthrough, we might still see that demand grows so rapidly that frontier labs need not slow their buildout spend, suggesting that the flywheel is fast enough to compensate for slow hardware progress. But if capabilities aren’t enough to drive revenue growth, spending will slow tremendously, and we, like Shannon, will be forced to watch the clock and ride the gradual wave of efficiency improvements for decades.
This post was written by Zach Brown and Alex Fogelson. Neil Thompson provided editorial support. Lucy Yan provided logistical support.
Appendix: calculation details
ENIAC: To calculate the cost of training Claude using ENIAC, we use its true lifecycle of 9 years, an initial build-out cost of $487,000, a max power draw of 150 kW, an estimated power cost of $0.02 per kWh, and FLOP rate of 500 FLOPS. The cost per FLOP is assuming it operates at maximum FLOPS and power capacity for 9 years, and the final cost is converted to 2026 dollars with a 16.93 inflation multiplier. We don’t estimate the utilization for ENIAC. Our final number is about 9 billion trillion dollars in 2026.
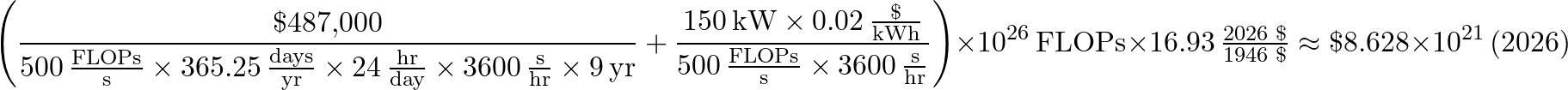
TITAN: To calculate the cost of training Claude using TITAN, we use both the initial cost of construction and the cost of a one time upgrade, totalling $97 million, amortized over its seven year lifespan. For power draw, we estimate a cost per kWh of $0.06 and a max power draw of 8200 kW. The peak FLOPS for TITAN was 27e15, though we assume 25% utilization, which was deemed historically reasonable by Claude Opus and GPT 5.5. Again adjusting for 2026 dollars, we get $12 billion dollars:
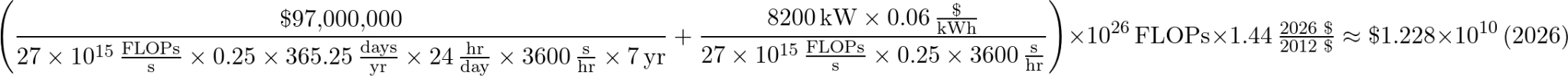
Claude, Today: Finally, for our modern day Claude estimations, we use an approximate cost per hour of renting an H100 of $1.50, a utilization of 40%, and a peak FLOP rate of 990 TFLOPS to get $105 million.
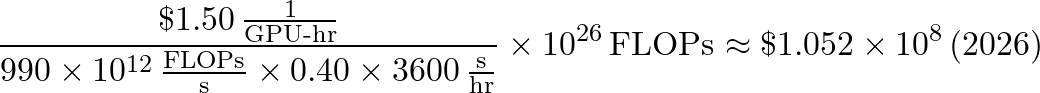
Other large datasets of natural language text similarly depend on compute: at-scale digitization of library print holdings in machine-readable format requires high-quality optical character recognition (OCR) technology, which is itself an AI technology that improves with training compute scale.
Though in our later historical cost estimates we don’t estimate the price of generating internet scale data, this isn’t to say this cost is zero. Hardware was no doubt a prerequisite for the internet, but the person-hours needed to populate its contents would be incredibly costly. For simplicity, we focus on compute as the primary data bottleneck going forward.
Using approximate rates of 1.5x per year between 1946 and 2012, 4.3x per year between 2012 and today.
 | A guest post by
|
 | A guest post by
|
This is awesome! Fact is we are capable of doing the impossible only 75 years ago!